
July 27, 2021 From rOpenSci (https://deploy-preview-304--ropensci.netlify.app/blog/2021/07/27/censo2017-es/). Except where otherwise noted, content on this site is licensed under the CC-BY license.
Consulta la versión en inglés de esta entrada del blog: The Story Behind censo2017, the First rOpenSci Package to be Reviewed in Spanish
🔗 Resumen
censo2017 es un paquete en R diseñado para organizar los archivos Redatam1 proporcionados por el Instituto Nacional de Estadísticas de Chile en formato DVD2. Este paquete fue inspirado por citesdb (Noam Ross, 2020) y taxadb (Carl Boettiger et al, 2021). Esta entrada trata sobre este paquete, el problema que resuelve, cómo usarlo, y el hecho de que el paquete y su proceso de revisión se hicieron íntegramente en español.
🔗 El desafío del censo
La motivación para haber completado esto es que, hace ya casi dos años, tuve que completar una tarea que me exigía extraer datos del mencionado DVD y se me complicó mucho.
Tuve que pedir prestado un portátil con Windows y conseguir un lector de DVD externo para poder leer esos archivos REDATAM y obtener algunos resúmenes de población con un software específico para ese formato. Para mi sorpresa, la tarea empezó a complicarse cada vez más, hasta el punto de querer exportar los datos a SQL para facilitar la extracción de datos.
Mi objetivo no era extraer secretos estadísticos, lo cual no es posible con estos conjuntos de datos, sólo quería obtener valores de población por intervalos de edad para diferentes regiones, entre otras agregaciones similares, que es algo que dplyr y otras herramientas facilitan mucho. Después de poder convertir los conjuntos de datos y la descripción de las variables a CSV/XML, descubrí que el esfuerzo de hacerlo justificaba la creación de un paquete de R para organizar mi trabajo.
🔗 El largo camino hacia la simplicidad
El Conversor REDATAM permite exportar bases de datos REDATAM completas en CSV para su uso en, por ejemplo, R o Python. Lamentablemente, esta herramienta también es exclusiva de Windows, y como usuario de Linux quería que los conjuntos de datos del censo estuvieran fácilmente disponibles para todas las plataformas.
Además de REDATAM, usar CSV para un censo no es la mejor opción, ya que implica leer tablas de 4 GB desde el disco. Esto es tan grande que la mayoría de los ordenadores portátiles no podrán realizar uniones, independientemente de la herramienta que se utilice (R, Python o subherramientas como readr o data.table, por mencionar algunas herramientas excelentes). Sin embargo, el uso de una herramienta basada en SQL, como DuckDB, permite realizar consultas eficientes y permite que la mayoría de las operaciones de censo sean posibles en un portátil común.
censo2017 crea una base de datos local e integrada DuckDB que simplifica el análisis de los conjuntos de datos del censo. Permite una consulta eficiente y es accesible a través de una interfaz compatible con DBI. El paquete también proporciona un panel interactivo para RStudio que permite explorar la base de datos y previsualizar los datos. El objetivo final de este trabajo es facilitar el acceso a los datos a los investigadores en Humanidades y Ciencias Sociales.
🔗 ¿Cómo funciona censo2017?
Para una rápida ilustración, supongamos que no hemos instalado el paquete y la base de datos local, que son dos pasos separados.
# instalar, cargar el paquete y crear base de datos local
remotes::install_github("ropensci/censo2017")
library(censo2017)
censo_descargar()
# para usar collect() y expresiones regulares
library(dplyr)
Sabemos que hay aproximadamente 17 millones de habitantes en Chile, pero ¿cuántos de ellos son hombres/mujeres? ¿Qué edad tienen los chilenos? ¿Cuántos de ellos asistieron a la universidad/instituto profesional? ¿Cuántos de ellos trabajan en cada rama de actividad económica3? Las preguntas censales “p08”, “p09”, “p15” y “p18” nos entregan esta información.
Este paquete cuenta con una tabla de metadatos (variables) que no forma parte de los archivos originales, ya que fue inferida de la estructura de REDATAM, que nos indica a qué tabla pertenece cada variable. Por ejemplo, utilizando dplyr podemos buscar descripciones que coincidan con “Curso”.
tbl(censo_conectar(), "variables") %>%
collect() %>%
filter(grepl("Curso", descripcion))
tabla variable descripcion tipo rango
<chr> <chr> <chr> <chr> <chr>
1 personas p14 Curso o Año Más Alto Aprobado integer 0 - 8
2 personas p15 Nivel del Curso Más Alto Aprobado integer 1 - 14
Aquellos que estén familiarizados con estos códigos podrán recordar cada valor de “p15”, pero afortunadamente para el resto de nosotros, este paquete también adjunta las etiquetas, por lo que cualquier usuario puede ver que “p15 = 12” significa “la persona asistió a la universidad”.
tbl(censo_conectar(), "variables_codificacion") %>%
collect() %>%
filter(variable == "p15")
tabla variable valor descripcion
<chr> <chr> <int> <chr>
1 personas p15 1 Sala Cuna o Jardín Infantil
2 personas p15 2 Prekínder
3 personas p15 3 Kínder
4 personas p15 4 Especial o Diferencial
5 personas p15 5 Educación Básica
6 personas p15 6 Primaria o Preparatoria (Sistema Antiguo)
7 personas p15 7 Científico-Humanista
8 personas p15 8 Técnica Profesional
9 personas p15 9 Humanidades (Sistema Antiguo)
10 personas p15 10 Técnica Comercial, Industrial/Normalista (Sistema Antiguo)
11 personas p15 11 Técnico Superior (1-3 Años)
12 personas p15 12 Profesional (4 o Más Años)
13 personas p15 13 Magíster
14 personas p15 14 Doctorado
15 personas p15 99 Valor Perdido
16 personas p15 98 No Aplica
Para obtener información detallada de cada municipio/región en relación con las preguntas anteriores, tenemos que pensar en los datos de REDATAM como un árbol, y es necesario unir “zonas” con “viviendas” por ID de zona, luego unir “viviendas” con “hogares” por ID de vivienda, y luego “hogares” con “personas” por ID de hogar. Esto se hace rápidamente con el backend DuckDB.
personas <- tbl(censo_conectar(), "zonas") %>%
mutate(
region = substr(as.character(geocodigo), 1, 2),
comuna = substr(as.character(geocodigo), 1, 5)
) %>%
select(region, comuna, geocodigo, zonaloc_ref_id) %>%
inner_join(select(tbl(censo_conectar(), "viviendas"),
zonaloc_ref_id, vivienda_ref_id), by = "zonaloc_ref_id") %>%
inner_join(select(tbl(censo_conectar(), "hogares"), vivienda_ref_id,
hogar_ref_id), by = "vivienda_ref_id") %>%
inner_join(select(tbl(censo_conectar(), "personas"), hogar_ref_id,
p08, p15, p18), by = "hogar_ref_id") %>%
collect()
Se puede obtener una rápida verificación con una cuenta. La tabla resultante tiene mucho sentido y refleja estadísticas resumidas de conocimiento común, como que en la capital (región #13) hay unos 7 millones de habitantes.
personas %>%
group_by(region) %>%
count()
region n
<chr> <int>
1 01 330558
2 02 607534
3 03 286168
4 04 757586
5 05 1815902
6 06 914555
7 07 1044950
8 08 2037414
9 09 957224
10 10 828708
11 11 103158
12 12 166533
13 13 7112808
14 14 384837
15 15 226068
Para conocer la proporción de hombres (1) y mujeres (2) por región, el código es muy similar.
personas %>%
group_by(region, p08) %>%
count() %>%
group_by(region) %>%
mutate(p = n / sum(n))
region p08 n p
<chr> <int> <int> <dbl>
1 01 1 167793 0.508
2 01 2 162765 0.492
3 02 1 315014 0.519
4 02 2 292520 0.481
5 03 1 144420 0.505
6 03 2 141748 0.495
7 04 1 368774 0.487
8 04 2 388812 0.513
9 05 1 880215 0.485
10 05 2 935687 0.515
# … with 20 more rows
En este punto obtuvimos agregaciones simples, pero siendo R un lenguaje estadístico, puede interesarte hacer inferencia. A modo de ejemplo, supongamos que la población sigue una distribución normal, por lo que tiene sentido encontrar la estimación del intervalo de confianza del 95% de la diferencia entre la proporción de hombres de la tercera edad4 y la proporción de mujeres de la tercera edad, cada una dentro de su grupo etario.
sexo_vs_edad <- tbl(censo_conectar(), "personas") %>%
select(sexo = p08, p09) %>%
mutate(anciano = ifelse(p09 >= 64, 1, 0)) %>%
group_by(sexo, anciano) %>%
count() %>%
# re-ordeno las etiquetas, lo hago en esta parte por eficiencia
mutate(
anciano = ifelse(anciano == 1, "1. anciano", "2. no-anciano"),
sexo = ifelse(sexo == 1, "1. masculino", "2. femenino")
) %>%
ungroup() %>%
collect()
sexo_vs_edad
sexo anciano n
<chr> <chr> <dbl>
1 1. masculino 2. no-anciano 7666728
2 2. femenino 2. no-anciano 7751676
3 1. masculino 1. anciano 935261
4 2. femenino 1. anciano 1220338
Antes de realizar una prueba de proporciones, tenemos que reordenar los datos y luego proceder a la prueba.
xtabs(n ~ anciano + sexo, sexo_vs_edad)
sexo
anciano 1. masculino 2. femenino
1. anciano 935261 1220338
2. no-anciano 7666728 7751676
prop.test(xtabs(n ~ anciano + sex, sex_vs_elder))
2-sample test for equality of proportions with continuity correction
data: xtabs(n ~ anciano + sexo, sexo_vs_edad)
X-squared = 30392, df = 1, p-value < 2.2e-16
alternative hypothesis: two.sided
95 percent confidence interval:
-0.06407740 -0.06266263
sample estimates:
prop 1 prop 2
0.4338752 0.4972452
La estimación del intervalo de confianza del 95% de la diferencia entre la proporción de hombres ancianos y no ancianos es de entre -6,4% y -6,3%, lo que está en consonancia con el hecho de que las mujeres tienden a tener una mayor esperanza de vida en Chile (consulta Statista para comparar). Lo que quería demostrar aquí es que usando este paquete, es muy fácil pasar datos a R, para poder realizar análisis de regresión u otros análisis estadísticos sobre la población chilena.
🔗 Integración de censo2017 con otros paquetes
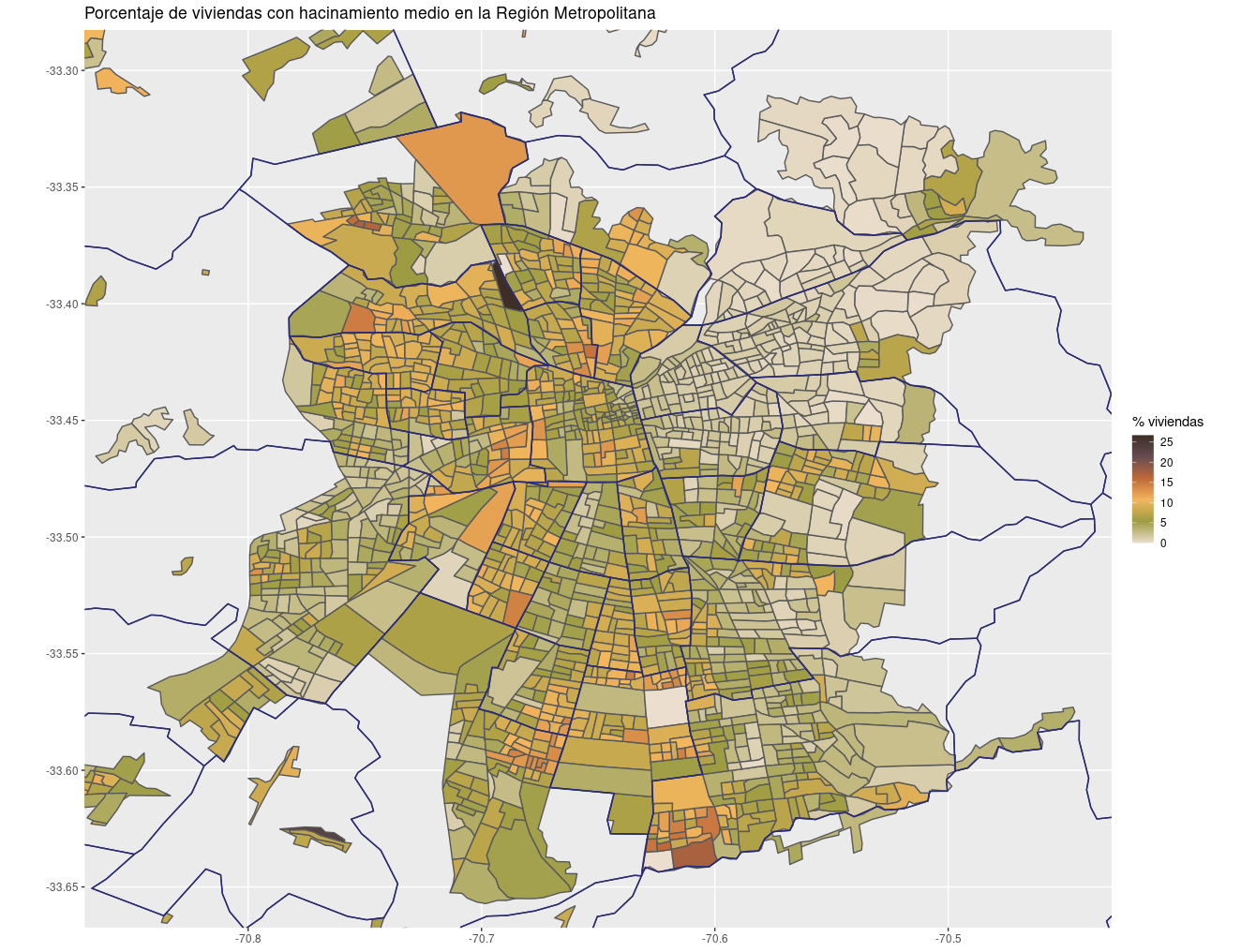
Se puede usar censo2017 con ggplot2 y otros paquetes de uso habitual. Para dar un ejemplo, es posible replicar diversos mapas de hacinamiento que han levantado desde Geógrafas Chile y el Centro de Producción del Espacio que dan cuenta del hacinamiento en la Región Metropolitana.
Para obtener esto, necesitasla cantidad de personas por vivienda y la cantidad de dormitorios de las viviendas. Puedes obtener las columnas correspondientes de la misma forma que se hizo en los ejemplos anteriores.
tbl(censo_conectar(), "variables") %>%
collect() %>%
filter(grepl("Pers", descripcion))
tabla variable descripcion tipo rango
<chr> <chr> <chr> <chr> <chr>
1 personas personan Número de la Persona integer 0 - 9999
2 viviendas cant_per Cantidad de Personas integer 0 - 9999
tbl(censo_conectar(), "variables") %>%
collect() %>%
filter(grepl("Dorm", descripcion))
tabla variable descripcion tipo rango
<chr> <chr> <chr> <chr> <chr>
1 viviendas p04 Número de Piezas Usadas Exclusivamente Como Dormitorio integer 0 - 6
Con las variables “cant_per” y “p04” se podría seguir la metodología del Ministerio de Desarrollo Social, que consiste en tomar la razón entre el número de personas residentes en la vivienda y el número de dormitorios de la misma y luego se tramifica la variable en las siguientes categorías:
- Sin hacinamiento [0;2,5)
- Medio [2,5;3,5)
- Alto [3,5;4,9)
- Crítico [5,+∞)
Puedes obtener la tabla con el índice de hacinamiento para cada vivienda con el siguiente código.
hacinamiento <- tbl(censo_conectar(), "zonas") %>%
mutate(
region = substr(as.character(geocodigo), 1, 2),
provincia = substr(as.character(geocodigo), 1, 3),
comuna = substr(as.character(geocodigo), 1, 5)
) %>%
filter(region == 13) %>%
select(comuna, geocodigo, zonaloc_ref_id) %>%
inner_join(select(tbl(censo_conectar(), "viviendas"), zonaloc_ref_id,
vivienda_ref_id, cant_per, p04),
by = "zonaloc_ref_id") %>%
mutate(
cant_per = as.numeric(cant_per),
p04 = as.numeric(p04),
p04 = case_when(
p04 == 98 ~ NA_real_,
p04 == 99 ~ NA_real_,
TRUE ~ as.numeric(p04)
)
) %>%
filter(!is.na(p04)) %>%
mutate(
# Indice Hacinamiento (variables a nivel vivienda)
ind_hacinam = case_when(
# con esto divido la cant de personas por pieza (si piezas >= 1) y
# tambien si es igual a cero (donde aplica pieza cero + 1 para casos
# como apartamento studio, etc)
p04 >=1 ~ cant_per / p04,
p04 ==0 ~ cant_per / (p04 + 1)
)
) %>%
mutate(
# Categorias hacinamiento
hacinam = case_when(
ind_hacinam < 2.5 ~ "Sin Hacinamiento",
ind_hacinam >= 2.5 & ind_hacinam < 3.5 ~ "Medio",
ind_hacinam >= 3.5 & ind_hacinam < 5 ~ "Alto",
ind_hacinam >= 5 ~ "Crítico"
)
) %>%
collect()
Para obtener los porcentajes, puedes agregar para obtener las cuentas correspondientes, teniendo en cuenta que no se debe ignorar los ceros, en especial si quieres visualizar la información, o tendrás áreas con vacíos en el mapa. Para esto se usará tidyr y janitor para tener una columna para cada categoria de hacinamiento.
library(tidyr)
library(janitor)
hacinamiento1 <- hacinamiento %>%
group_by(geocodigo, hacinam) %>%
count()
hacinamiento2 <- expand_grid(
geocodigo = unique(hacinamiento$geocodigo),
hacinam = c("Sin Hacinamiento", "Medio", "Alto", "Crítico")
)
hacinamiento2 <- hacinamiento2 %>%
left_join(hacinamiento1) %>%
pivot_wider(names_from = "hacinam", values_from = "n") %>%
clean_names() %>%
mutate_if(is.numeric, function(x)
case_when(is.na(x) ~ 0, TRUE ~ as.numeric(x))) %>%
mutate(
total_viviendas = sin_hacinamiento + medio + alto + critico,
prop_sin = 100 * sin_hacinamiento / total_viviendas,
prop_medio = 100 * medio / total_viviendas,
prop_alto = 100 * alto / total_viviendas,
prop_critico = 100 * critico / total_viviendas
)
hacinamiento2
# # A tibble: 2,421 x 10
# geocodigo sin_hacinamiento medio alto critico total_viviendas prop_sin prop_medio prop_alto prop_critico
# <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
# 1 13101011001 1072 28 2 2 1104 97.1 2.54 0.181 0.181
# 2 13101011002 1127 57 14 7 1205 93.5 4.73 1.16 0.581
# 3 13101011003 1029 23 6 4 1062 96.9 2.17 0.565 0.377
# 4 13101011004 801 49 18 13 881 90.9 5.56 2.04 1.48
# 5 13101011005 886 49 9 5 949 93.4 5.16 0.948 0.527
# 6 13101021001 1219 107 35 16 1377 88.5 7.77 2.54 1.16
# 7 13101021002 1223 78 15 7 1323 92.4 5.90 1.13 0.529
# 8 13101021003 1173 105 34 9 1321 88.8 7.95 2.57 0.681
# 9 13101021004 1199 110 47 14 1370 87.5 8.03 3.43 1.02
# 10 13101021005 826 87 29 10 952 86.8 9.14 3.05 1.05
# # … with 2,411 more rows
Ahora estás en condiciones de crear un mapa. Se muestra el mapa de hacinamiento medio a modo de ejemplo, los otros casos quedan como ejercicio.
# if (!require("colRoz")) remotes::install_github("jacintak/colRoz")
library(chilemapas)
library(colRoz)
ggplot() +
geom_sf(data = inner_join(hacinamiento2, mapa_zonas),
aes(fill = prop_medio, geometry = geometry)) +
geom_sf(data = filter(mapa_comunas, codigo_region == "13"),
aes(geometry = geometry), colour = "#2A2B75", fill = NA) +
ylim(-33.65, -33.3) +
xlim(-70.85, -70.45) +
scale_fill_gradientn(colors = rev(colRoz_pal("ngadju")), name = "% viviendas hacinadas") +
labs(title = "Porcentaje de viviendas con hacinamiento medio en la Región Metropolitana")
🔗 Enlaces con formación y políticas
El uso de formatos abiertos en sí mismo facilita el trabajo, ya que reduce los problemas de compatibilidad a la hora de leer los datos, pero los conjuntos de datos tienen que incluir la documentación adecuada, no sólo estar disponibles en formatos adecuados. Para el caso particular de censo2017, hace más equitativos los recursos para la educación e investigación, ya que ayuda a cualquier institución que realice cursos de estadística aplicada o investigación a realizar análisis estadísticos censales independientemente de las herramientas que utilicen, y enfocarse en una región o en cualquier grupo de interés, como la población indígena, los ancianos o las personas que viven en departamentos.
La base de datos censales que proporciono dentro del paquete puede ser leída en Python, Java C++, node.js e incluso desde una línea de comandos, y es importante mencionar que es multiplataforma. Para el caso del análisis estadístico aplicado basado en GUI, censo2017 hace muy fácil la exportación de subconjuntos a Microsoft Excel o Google Sheets, sin las desventajas del formato original del censo anteriormente comentado, e incluso a Stata y SPSS gracias al ecosistema de paquetes R.
Los que, como yo, escribimos paquetes R podemos hacer nuestra contribución creando herramientas que puedan ayudar a los países de la región a retomar el camino hacia el logro de los Objetivos de Desarrollo Sostenible definidos por las Naciones Unidas, incluso a pesar del reciente aumento del proteccionismo, la incertidumbre política y la actitud poco clara hacia el régimen comercial mundial que se observa en América Latina. Desarrollar y promover una política reflexiva es la única manera de decir “jaque mate” al subdesarrollo.
🔗 Contribución de la comunidad rOpenSci
La ayuda de rOpenSci y su revisión de software fue fundamental. Los revisores, María Paula Caldas, Frans van Dunné y Melina Vidoni probaron el paquete y sugirieron mejoras. Sus revisiones fueron muy útiles, dieron consejos muy valiosos y apoyaron mucho mi trabajo y el desarrollo del paquete.
El lector interesado encontrará un registro completo de todos los cambios realizados durante el proceso de revisión, donde todo está comentado en español, y habrá nuevos paquetes rOpenSci en idiomas distintos del inglés. Desde 2011, rOpenSci ha estado creando infraestructura técnica en forma de herramientas de software R que reducen las barreras para trabajar con datos científicos. Recuerdo la charla de mi amiga y colega Riva Quiroga, donde destaca que iniciativas como ésta no son sólo software, sino herramientas para hacer más fuerte a la comunidad.
Me encantaría ver diferentes “copias” de censo2017 en los países vecinos Perú y Bolivia, y el resto de la región. Crear el primer paquete de rOpenSci totalmente documentado en español no sólo tiene que ver con la inclusión, que obviamente es deseable. También tiene que ver con la productividad, porque en América Latina los materiales que están documentados en inglés son difíciles de entender y por lo tanto las herramientas no son adoptadas como uno quisiera. Así como la infraestructura de R4DS en español motivó la creación de R4DS en portugués, espero que censo2017 abra la puerta a colaboraciones interesantes y paquetes similares en diferentes idiomas.
Creo que hago lo mejor que puedo para contribuir a iniciativas como rOpenSci porque aquí he encontrado mi lugar y he descubierto a otros que tienen el deseo de aprender muchas cosas diferentes. Mi contribución actual es hacer que los datos, las herramientas y las mejores prácticas sean más descubribles, contribuyendo al mismo tiempo a la infraestructura social.
-
Redatam es un software muy utilizado para la difusión de censos de población. Aunque su uso es gratuito, utiliza un formato cerrado. ↩︎
-
Para el periodo de junio de 2018 a diciembre de 2019, el Censo estaba disponible en formatos DVD y en REDATAM únicamente. Ahora está disponible en línea en formatos REDATAM, SPSS y CSV. ↩︎
-
Para el caso de Chile, la división más agregada de la actividad económica separa la producción en doce ramas: Agricultura y pesca; minería; industria manufacturera; electricidad, gas y agua; construcción; comercio minorista, hoteles y restaurantes; transporte, comunicaciones e información; servicios financieros; actividades inmobiliarias; servicios empresariales; servicios personales; administración pública. Para una descripción más detallada, puedes explorar la Matriz Input-Output de la economía chilena y/o el paquete leontief para el análisis sectorial. ↩︎
-
Desde el punto de vista metodológico, es más fácil contar a las personas de 64 años o más (la edad legal para ser considerado anciano), que contar a los jubilados, ya que algunos sectores permiten jubilarse más tarde y otros no, y la decisión se deja al acuerdo entre el trabajador y la empresa. ↩︎
